使用线程池的优点ThreadPoolExecutorExecutors工具类newFixedThreadPoolnewCachedThreadPoolnewSingleThreadExecutornewScheduledThreadPool延迟执行和周期性执行的原理最佳实践合理地创建线程池多线程如何提升性能创建多少线程合适?CPU 密集型运算I/O 密集型运算异常处理Fork/Join开源框架实现的线程池tomcat自定义线程池实现
使用线程池的优点
- 降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
ThreadPoolExecutor
ThreadPoolExecutor原理Executors工具类
concurrent包提供了Executors工具类,利用它可以创建各种不同类型的线程池。
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
特点
核心线程数 = 最大线程数(没有救急线程被创建),因此也无需超时时间阻塞队列是无界的,可以放任意数量的任务
评价 适用于任务量已知,相对耗时的任务
newCachedThreadPool
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
特点
- 核心线程数是 0, 最大线程数是 Integer.MAX_VALUE,救急线程的空闲生存时间是 60s,意味着 全部都是救急线程(60s 后可以回收),救急线程可以无限创建
- 队列采用了
SynchronousQueue实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交 货)
评价 整个线程池表现为线程数会根据任务量不断增长,没有上限,当任务执行完毕,空闲 1分钟后释放线 程。 适合任务数比较密集,但每个任务执行时间较短的情况
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
使用场景:
希望多个任务排队执行。线程数固定为 1,任务数多于 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程 也不会被释放。
与自己单独创建线程的区别:自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一 个线程,保证池的正常工作
与 newFixedThreadPool(1) 的区别
- Executors.newSingleThreadExecutor() 线程个数始终为1,不能修改.FinalizableDelegatedExecutorService 应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因 此不能调用 ThreadPoolExecutor 中特有的方法
- Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改 对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改
newScheduledThreadPool
整个线程池表现为:线程数固定,任务数多于线程数时,会放入无界队列排队。任务执行完毕,这些线程也不会被释放。用来执行延迟或反复执行的任务
在『任务调度线程池』功能加入之前,可以使用 java.util.Timer 来实现定时功能,Timer 的优点在于简单易用,但 由于所有任务都是由同一个线程来调度,因此所有任务都是串行执行的,同一时间只能有一个任务在执行,前一个 任务的延迟或异常都将会影响到之后的任务
public static void main(String[] args) { Timer timer = new Timer(); TimerTask task1 = new TimerTask() { @Override public void run() { log.debug("task 1"); sleep(2); } }; TimerTask task2 = new TimerTask() { @Override public void run() { log.debug("task 2"); } }; // 使用 timer 添加两个任务,希望它们都在 1s 后执行 // 但由于 timer 内只有一个线程来顺序执行队列中的任务,因此『任务1』的延时,影响了『任务2』的执行 timer.schedule(task1, 1000); timer.schedule(task2, 1000); }
输出
20:46:09.444 c.TestTimer [main] - start... 20:46:10.447 c.TestTimer [Timer-0] - task 1 20:46:12.448 c.TestTimer [Timer-0] - task 2
使用 ScheduledExecutorService 改写
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2); // 添加两个任务,希望它们都在 1s 后执行 executor.schedule(() -> { System.out.println("任务1,执行时间:" + new Date()); try { Thread.sleep(2000); } catch (InterruptedException e) {} }, 1000, TimeUnit.MILLISECONDS); executor.schedule(() -> { System.out.println("任务2,执行时间:" + new Date()); }, 1000, TimeUnit.MILLISECONDS);
输出
任务1,执行时间:Thu Jan 03 12:45:17 CST 2019 任务2,执行时间:Thu Jan 03 12:45:17 CST 2019
延迟执行任务


周期执行任务


区别如下:
AtFixedRate:按固定频率执行,与任务本身执行时间无关。但有个前提条件,任务执行时间必须小于间隔时间,例如间隔时间是5s,每5s执行一次任务,任务的执行时间必须小于5s。
WithFixedDelay:按固定间隔执行,与任务本身执行时间有关。例如,任务本身执行时间是10s,间隔2s,则下一次开始执行的时间就是12s。scheduleAtFixedRate 例子:
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1); log.debug("start..."); pool.scheduleAtFixedRate(() -> { log.debug("running..."); }, 1, 1, TimeUnit.SECONDS);
输出
21:45:43.167 c.TestTimer [main] - start... 21:45:44.215 c.TestTimer [pool-1-thread-1] - running... 21:45:45.215 c.TestTimer [pool-1-thread-1] - running... 21:45:46.215 c.TestTimer [pool-1-thread-1] - running... 21:45:47.215 c.TestTimer [pool-1-thread-1] - running...
scheduleAtFixedRate 例子(任务执行时间超过了间隔时间):
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1); log.debug("start..."); pool.scheduleAtFixedRate(() -> { log.debug("running..."); sleep(2); }, 1, 1, TimeUnit.SECONDS);
输出分析:一开始,延时 1s,接下来,由于任务执行时间 > 间隔时间,间隔被撑到了 2s
21:44:30.311 c.TestTimer [main] - start... 21:44:31.360 c.TestTimer [pool-1-thread-1] - running... 21:44:33.361 c.TestTimer [pool-1-thread-1] - running... 21:44:35.362 c.TestTimer [pool-1-thread-1] - running... 21:44:37.362 c.TestTimer [pool-1-thread-1] - running...
scheduleWithFixedDelay 例子:
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1); log.debug("start..."); pool.scheduleWithFixedDelay(()-> { log.debug("running..."); sleep(2); }, 1, 1, TimeUnit.SECONDS);
输出分析:一开始,延时 1s,scheduleWithFixedDelay 的间隔是 上一个任务结束 <-> 延时 <-> 下一个任务开始 所 以间隔都是 3s
21:40:55.078 c.TestTimer [main] - start... 21:40:56.140 c.TestTimer [pool-1-thread-1] - running... 21:40:59.143 c.TestTimer [pool-1-thread-1] - running... 21:41:02.145 c.TestTimer [pool-1-thread-1] - running... 21:41:05.147 c.TestTimer [pool-1-thread-1] - running...
延迟执行和周期性执行的原理
ScheduledThreadPoolExecutor继承了ThreadPoolExecutor,这意味着其内部的数据结构和ThreadPoolExecutor是基本一样的,那它是如何实现延迟执行任务和周期性执行任务的呢?
延迟执行任务依靠的是DelayQueue。DelayQueue是 BlockingQueue的一种,其实现原理是二叉堆。
而周期性执行任务是执行完一个任务之后,再把该任务扔回到任务队列中,如此就可以对一个任务反复执行。
不过这里并没有使用DelayQueue,而是在ScheduledThreadPoolExecutor内部又实现了一个特定的DelayQueue。


其原理和DelayQueue一样,但针对任务的取消进行了优化。下面主要讲延迟执行和周期性执行的实现过程。
延迟执行


传进去的是一个Runnable,外加延迟时间delay。在内部通过decorateTask(...)方法把Runnable包装成一个ScheduleFutureTask对象,而DelayedWorkQueue中存放的正是这种类型的对象,这种类型的对象一定实现了Delayed接口。




从上面的代码中可以看出,schedule()方法本身很简单,就是把提交的Runnable任务加上delay时间,转换成ScheduledFutureTask对象,放入DelayedWorkerQueue中。任务的执行过程还是复用的ThreadPoolExecutor,延迟的控制是在DelayedWorkerQueue内部完成的。
周期性执行




和schedule(...)方法的框架基本一样,也是包装一个ScheduledFutureTask对象,只是在延迟时间参数之外多了一个周期参数,然后放入DelayedWorkerQueue就结束了。
两个方法的区别在于一个传入的周期是一个负数,另一个传入的周期是一个正数,为什么要这样做呢?
用于生成任务序列号的sequencer,创建ScheduledFutureTask的时候使用:


private class ScheduledFutureTask<V> extends FutureTask<V> implements RunnableScheduledFuture<V> { private final long sequenceNumber; private volatile long time; private final long period; ScheduledFutureTask(Runnable r, V result, long triggerTime,long period, long sequenceNumber) { super(r, result); this.time = triggerTime; // 延迟时间 this.period = period; // 周期 this.sequenceNumber = sequenceNumber; } // 实现Delayed接口 public long getDelay(TimeUnit unit) { return unit.convert(time - System.nanoTime(), NANOSECONDS); } // 实现Comparable接口 public int compareTo(Delayed other) { if (other == this) // compare zero if same object return 0; if (other instanceof ScheduledFutureTask) { ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other; long diff = time - x.time; if (diff < 0) return -1; else if (diff > 0) return 1; // 延迟时间相等,进一步比较序列号 else if (sequenceNumber < x.sequenceNumber) return -1; else return 1; } long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS); return (diff < 0) ? -1 : (diff > 0) ? 1 : 0; } // 实现Runnable接口 public void run() { if (!canRunInCurrentRunState(this)) cancel(false); // 如果不是周期执行,则执行一次 else if (!isPeriodic()) super.run(); // 如果是周期执行,则重新设置下一次运行的时间,重新入队列 else if (super.runAndReset()) { setNextRunTime(); reExecutePeriodic(outerTask); } } // 下一次执行时间 private void setNextRunTime() { long p = period; if (p > 0) time += p; else time = triggerTime(-p); } } // 下一次触发时间 long triggerTime(long delay) { return System.nanoTime() + ((delay < (Long.MAX_VALUE >> 1)) ? delay : overflowFree(delay)); } // 放到队列中,等待下一次执行 void reExecutePeriodic(RunnableScheduledFuture<?> task) { if (canRunInCurrentRunState(task)) { super.getQueue().add(task); if (canRunInCurrentRunState(task) || !remove(task)) { ensurePrestart(); return; } } task.cancel(false); }
withFixedDelay和atFixedRate的区别就体现在setNextRunTime里面。
如果是atFixedRate,period>0,下一次开始执行时间等于上一次开始执行时间+period;如果是withFixedDelay,period < 0,下一次开始执行时间等于triggerTime(-p),为now+(-period),now即上一次执行的结束时间。
最佳实践
不同类型的线程池,其实都是由前面的几个关键配置参数配置而成的。在《阿里巴巴Java开发手册》中,明确禁止使用Executors创建线程池,并要求开发者直接使用ThreadPoolExector或ScheduledThreadPoolExecutor进行创建。这样做是为了强制开发者明确线程池的运行策略,使其对线程池的每个配置参数皆做到心中有数,以规避因使用不当而造成资源耗尽的风险。
合理地创建线程池
多线程如何提升性能
使用多线程,本质上就是提升程序性能。
度量性能的指标有很多,但是有两个指标是最核心的,它们就是延迟和吞吐量。
延迟指的是发出请求到收到响应这个过程的时间;延迟越短,意味着程序执行得越快,性能也就越好。 吞吐量指的是在单位时间内能处理请求的数量;吞吐量越大,意味着程序能处理的请求越多,性能也就越好。这两个指标内部有一定的联系(同等条件下,延迟越短,吞吐量越大),但是由于它们隶属不同的维度(一个是时间维度,一个是空间维度),并不能互相转换。
我们所谓提升性能,从度量的角度,主要是降低延迟,提高吞吐量。
要想“降低延迟,提高吞吐量”,对应的方法呢,基本上有两个方向,一个方向是优化算法,另一个方向是将硬件的性能发挥到极致。前者属于算法范畴,后者则是和并发编程息息相关了。那计算机主要有哪些硬件呢?主要是两类:一个是 I/O,一个是 CPU。
简言之,在并发编程领域,提升性能本质上就是提升硬件的利用率,再具体点来说,就是提升 I/O 的利用率和 CPU 的利用率。
例如操作系统已经解决了磁盘和网卡的利用率问题,利用中断机制还能避免 CPU 轮询 I/O 状态,也提升了 CPU 的利用率。
但是操作系统解决硬件利用率问题的对象往往是单一的硬件设备,而我们的并发程序,往往需要 CPU 和 I/O 设备相互配合工作,也就是说,我们需要解
决 CPU 和 I/O 设备综合利用率的问题。
关于这个综合利用率的问题,操作系统虽然没有办法完美解决,但是却给我们提供了方案,那就是:多线程。
下面我们用一个简单的示例来说明:如何利用多线程来提升 CPU 和 I/O 设备的利用率?假设程序按照 CPU 计算和 I/O 操作交叉执行的方式运行,而且 CPU 计算和 I/O 操作的耗时是 1:1。
如下图所示,如果只有一个线程,执行 CPU 计算的时候,I/O 设备空闲;执行 I/O 操作的时候,CPU 空闲,所以 CPU 的利用率和 I/O 设备的利用率都是 50%。


如果有两个线程,如下图所示,当线程 A 执行 CPU 计算的时候,线程 B 执行 I/O 操作;当线程 A 执行 I/O 操作的时候,线程 B 执行 CPU 计算,这样 CPU 的利用率和 I/O 设备的利用率就都达到了 100%。


我们将 CPU 的利用率和 I/O 设备的利用率都提升到了 100%,会对性能产生了哪些影响呢?通过上面的图示,很容易看出:单位时间处理的请求数量翻了一番,也就是说吞吐量提高了 1 倍。此时可以逆向思维一下,如果 CPU 和 I/O 设备的利用率都很低,那么可以尝试通过增加线程来提高吞吐量。
在单核时代,多线程主要就是用来平衡 CPU 和 I/O 设备的。如果程序只有 CPU 计算,而没有 I/O 操作的话,多线程不但不会提升性能,还会使性能变得更差,原因是增加了线程切换的成本。但是在多核时代,这种纯计算型的程序也可以利用多线程来提升性能。为什么呢?因为利用多核可以降低响应时间。
举个简单的例子:
计算 1+2+… … +100 亿的值,如果在 4 核的 CPU 上利用 4 个线程执行,线程 A 计算 [1,25 亿),线程 B 计算 [25 亿,50 亿),线程 C 计算 [50,75 亿),线程 D 计算 [75 亿,100 亿],之后汇总,那么理论上应该比一个线程计算 [1,100 亿] 快将近 4 倍,响应时间能够降到 25%。一个线程,对于 4 核的 CPU,CPU 的利用率只有 25%,而 4 个线程,则能够将 CPU 的利用率提高到 100%。


创建多少线程合适?
过小会导致程序不能充分地利用系统资源、容易导致饥饿
过大会导致更多的线程上下文切换,占用更多内存
CPU 密集型运算
多线程本质上是提升多核 CPU 的利用率,所以对于一个 4 核的 CPU,每个核一个线程,理论上创建 4 个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于 CPU 密集型的计算场景,理论上“线程的数量 =CPU 核数”就是最合适的。
不过在工程上,线程的数量一般会设置为“CPU 核数 +1”,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证 CPU 的利用率。
I/O 密集型运算
对于 I/O 密集型的计算场景,比如前面我们的例子中,如果 CPU 计算和 I/O 操作的耗时是 1:1,那么 2 个线程是最合适的。如果 CPU 计算和 I/O 操作的耗时是 1:2,那多少个线程合适呢?是 3 个线程,如下图所示:CPU 在 A、B、C 三个线程之间切换,对于线程 A,当 CPU 从 B、C 切换回来时,线程 A 正好执行完 I/O 操作。这样 CPU 和 I/O 设备的利用率都达到了 100%。


CPU 不总是处于繁忙状态,例如,当你执行业务计算时,这时候会使用 CPU 资源,但当你执行 I/O 操作时、远程 RPC 调用时,包括进行数据库操作时,这时候 CPU 就闲下来了,你可以利用多线程提高它的利用率。
经验公式如下
线程数 = 核数 * 期望 CPU 利用率 * 总时间(CPU计算时间+IO等待时间) / CPU 计算时间例如 4 核 CPU 计算时间是 50% ,其它等待时间是 50%,期望 cpu 被 100% 利用,套用公式 4 * 100% * 100% / 50% = 8
例如 4 核 CPU 计算时间是 10% ,其它等待时间是 90%,期望 cpu 被 100% 利用,套用公式 4 * 100% * 100% / 10% = 40
异常处理
- 主动捕捉异常
ExecutorService pool = Executors.newFixedThreadPool(1); pool.submit(() -> { try { log.debug("task1"); int i = 1 / 0; } catch (Exception e) { log.error("error:", e); } });
- 使用Future
ExecutorService pool = Executors.newFixedThreadPool(1); Future<Boolean> f = pool.submit(() -> { log.debug("task1"); int i = 1 / 0; return true; }); log.debug("result:{}", f.get())
Fork/Join
Fork/Join线程池开源框架实现的线程池
tomcat

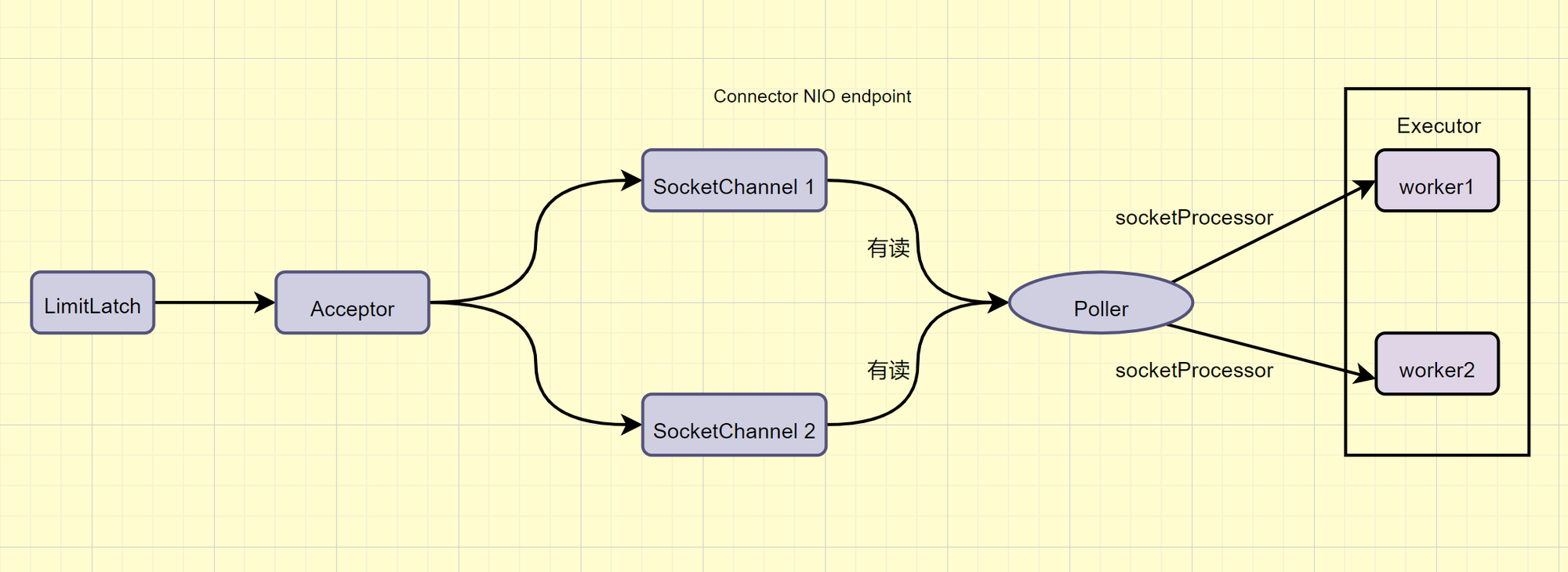
- LimitLatch用来限流,可以控制最大连接个数,类似JUC中的Semaphore
- Acceptor 只负责接收新的socket连接
- Poller 只负责监听 socket channel 是否有 可读的I/O事件
- 一旦可读,封装一个任务对象socketProcessor,提交给Executor线程池处理
- Executor 线程池中的工作线程最终负责处理请求
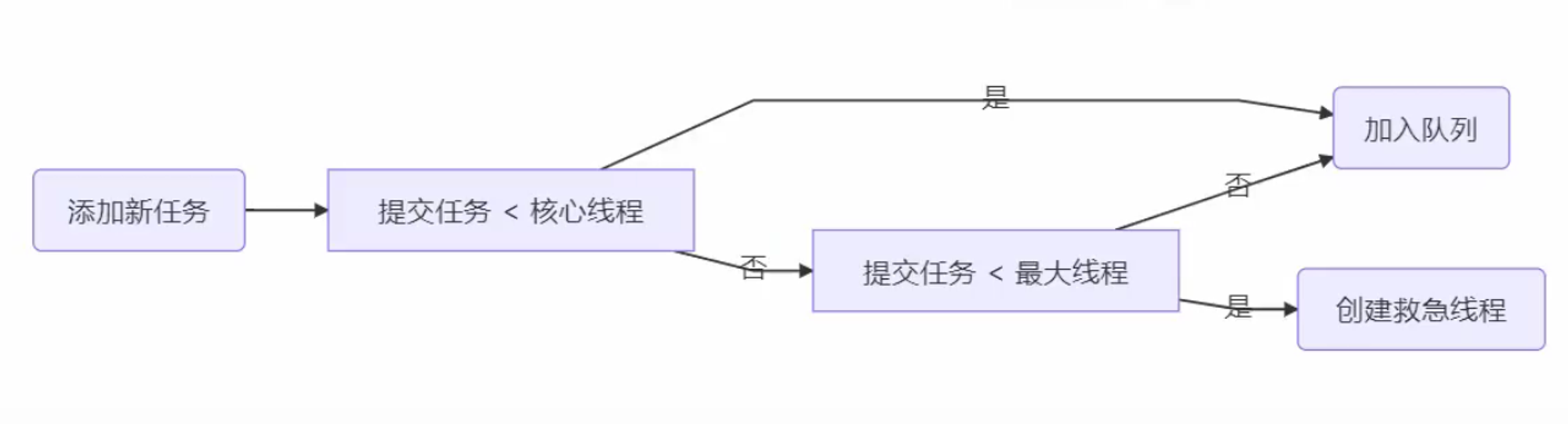
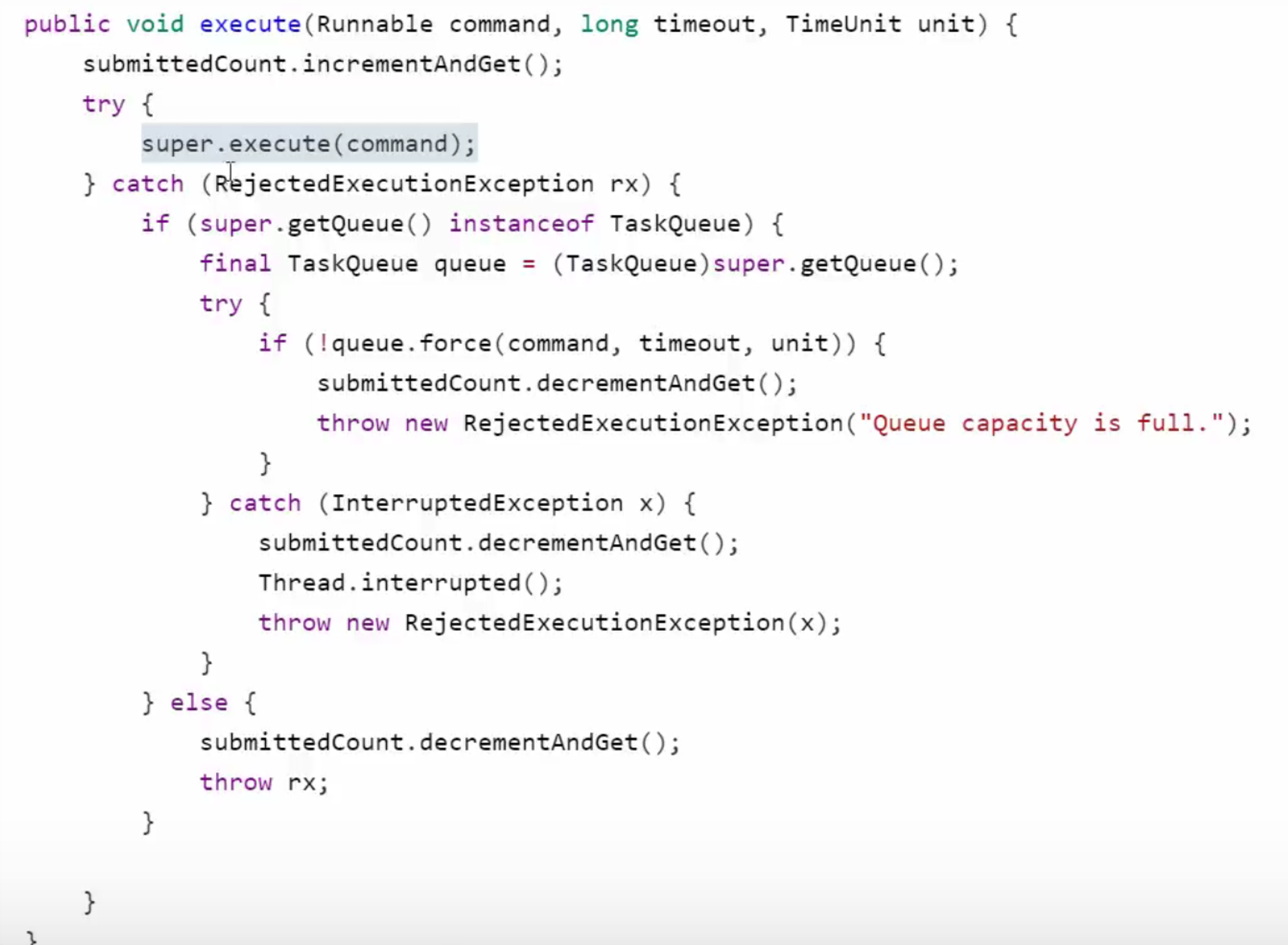
tomcat线程池扩展了ThreadPoolExecutor,行为稍有不同
- 如果总线程数达到maximumPoolSize ,这时不会立刻抛RejectedExecutionException 异常
- 而是再次尝试将任务放入队列,如果还失败,才抛出RejectedExecutionException 异常



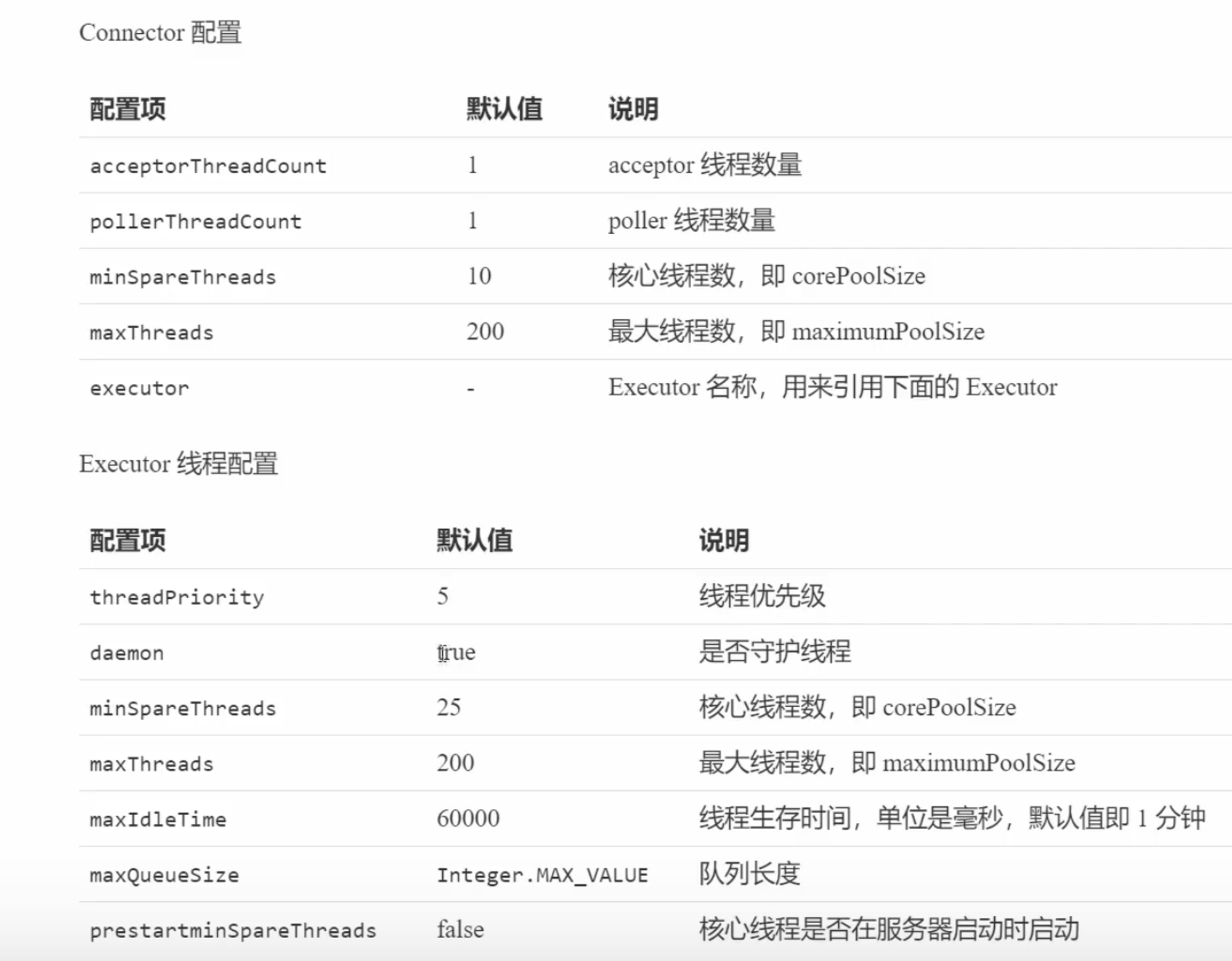
配置

work flow