

概念以及优点
Fork/Join 是 JDK 1.7 加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的 cpu 密集型 运算
所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计 算,如归并排序、斐波那契数列、都可以用分治思想进行求解
Fork/Join 在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成,进一步提升了运 算效率
可以将ForkJoinPool看作一个单机版的Map/Reduce,多个线程并行计算。
Fork/Join 默认会创建与 cpu 核心数大小相同的线程池
相比于ThreadPoolExecutor,ForkJoinPool可以更好地实现计算的负载均衡,提高资源利用率。
假设有5个任务,在ThreadPoolExecutor中有5个线程并行执行,其中一个任务的计算量很大,其余4个任务的计算量很小,这会导致1个线程很忙,其他4个线程则处于空闲状态。
利用ForkJoinPool,可以把大的任务拆分成很多小任务,然后这些小任务被所有的线程执行,从而实现任务计算的负载均衡。
基本使用
提交给 Fork/Join 线程池的任务需要继承 RecursiveTask(有返回值)或 RecursiveAction(没有返回值)


例子1:快排
快排有2个步骤:
- 利用数组的第1个元素把数组划分成两半,左边数组里面的元素小于或等于该元素,右边数组里面的元素比该元素大;
- 对左右的两个子数组分别排序。
左右两个子数组相互独立可以并行计算。利用ForkJoinPool,代码如下:
public class ForkJoinPoolDemo02 { static class SortTask extends RecursiveAction { final long[] array; final int lo; final int hi; public SortTask(long[] array) { this.array = array; this.lo = 0; this.hi = array.length - 1; } public SortTask(long[] array, int lo, int hi) { this.array = array; this.lo = lo; this.hi = hi; } private int partition(long[] array, int lo, int hi) { long x = array[hi]; int i = lo - 1; for (int j = lo; j < hi; j++) { if (array[j] <= x) { i++; swap(array, i, j); } } swap(array, i + 1, hi); return i + 1; } private void swap(long[] array, int i, int j) { if (i != j) { long temp = array[i]; array[i] = array[j]; array[j] = temp; } } @Override protected void compute() { if (lo < hi) { // 找到分区的元素下标 int pivot = partition(array, lo, hi); // 将数组分为两部分 SortTask left = new SortTask(array, lo, pivot - 1); SortTask right = new SortTask(array, pivot + 1, hi); left.fork(); right.fork(); left.join(); right.join(); } } } public static void main(String[] args) throws InterruptedException { long[] array = {5, 3, 7, 9, 2, 4, 1, 8, 10}; // 一个任务 ForkJoinTask sort = new SortTask(array); // 一个pool ForkJoinPool pool = new ForkJoinPool(); // ForkJoinPool开启多个线程,同时执行上面的子任务 pool.submit(sort); // 结束ForkJoinPool pool.shutdown(); // 等待结束Pool pool.awaitTermination(10, TimeUnit.SECONDS); System.out.println(Arrays.toString(array)); } }
例2 定义了一个对 1~n 之间的整数求和的任务
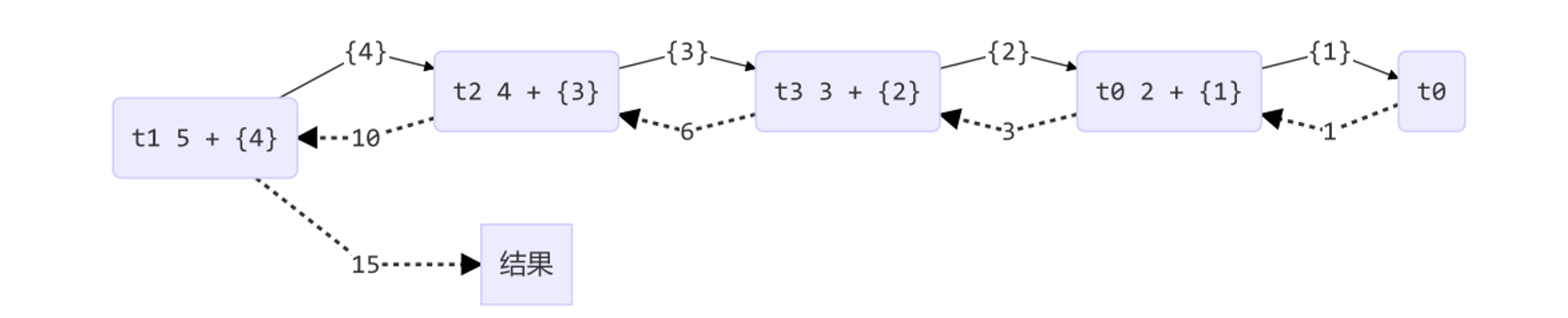
@Slf4j(topic = "c.TestForkJoin2") public class TestForkJoin2 { public static void main(String[] args) { ForkJoinPool pool = new ForkJoinPool(4); System.out.println(pool.invoke(new MyTask(5))); // new MyTask(5) 5+ new MyTask(4) 4 + new MyTask(3) 3 + new MyTask(2) 2 + new MyTask(1) } } // 1~n 之间整数的和 @Slf4j(topic = "c.MyTask") class MyTask extends RecursiveTask<Integer> { private int n; public MyTask(int n) { this.n = n; } @Override public String toString() { return "{" + n + '}'; } @Override protected Integer compute() { // 如果 n 已经为 1,可以求得结果了 if (n == 1) { log.debug("join() {}", n); return n; } // 将任务进行拆分(fork) AddTask1 t1 = new AddTask1(n - 1); t1.fork(); log.debug("fork() {} + {}", n, t1); // 合并(join)结果 int result = n + t1.join(); log.debug("join() {} + {} = {}", n, t1, result); return result; } }
输出
10:04:29.307 c.MyTask [ForkJoinPool-1-worker-1] - fork() 5 + {4} 10:04:29.307 c.AddTask [ForkJoinPool-1-worker-0] - fork() 2 + {1} 10:04:29.307 c.AddTask [ForkJoinPool-1-worker-2] - fork() 4 + {3} 10:04:29.307 c.AddTask [ForkJoinPool-1-worker-3] - fork() 3 + {2} 10:04:29.312 c.AddTask [ForkJoinPool-1-worker-0] - join() 1 10:04:29.312 c.AddTask [ForkJoinPool-1-worker-0] - join() 2 + {1} = 3 10:04:29.312 c.AddTask [ForkJoinPool-1-worker-3] - join() 3 + {2} = 6 10:04:29.312 c.AddTask [ForkJoinPool-1-worker-2] - join() 4 + {3} = 10 10:04:29.312 c.MyTask [ForkJoinPool-1-worker-1] - join() 5 + {4} = 15
调用流程

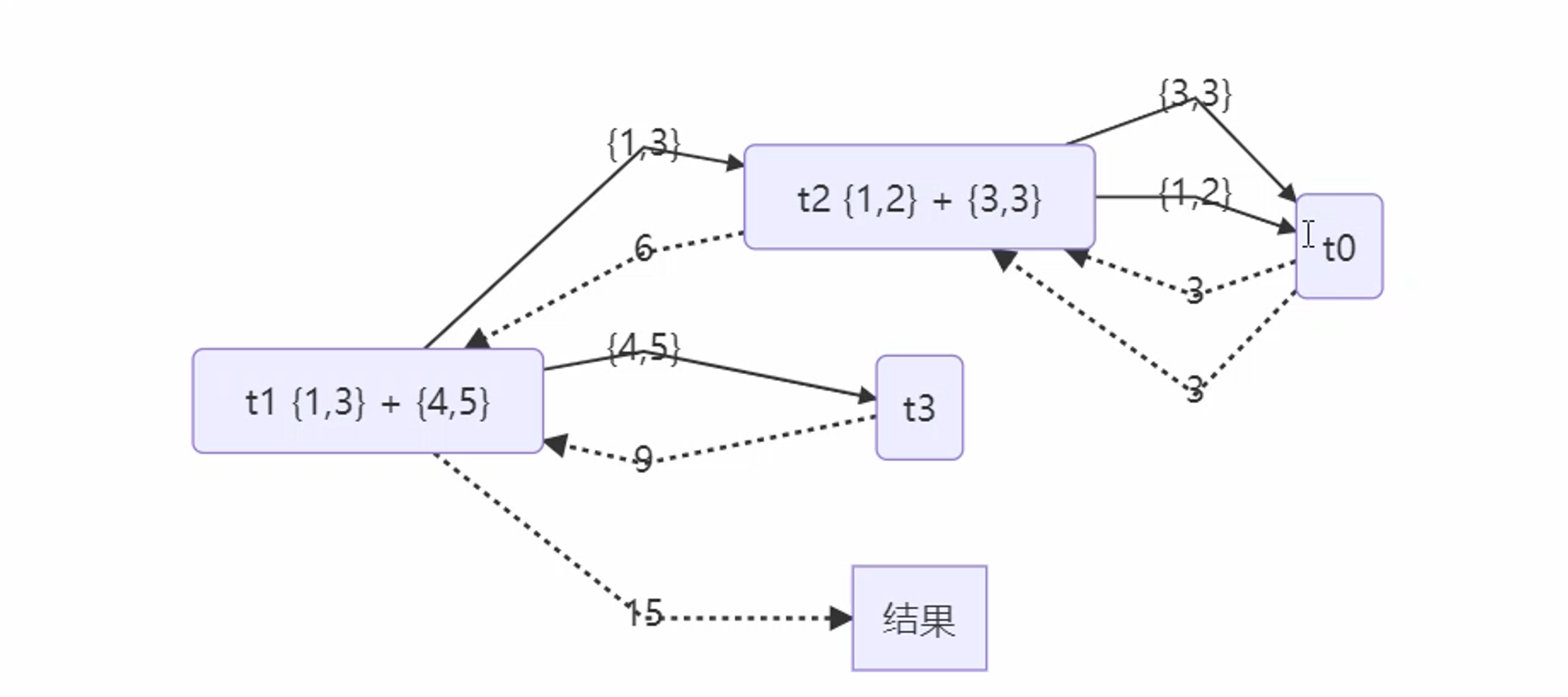
提高并行度改进
public class TestForkJoin { public static void main(String[] args) { ForkJoinPool pool = new ForkJoinPool(4); // System.out.println(pool.invoke(new AddTask1(5))); System.out.println(pool.invoke(new AddTask3(1, 5))); } } @Slf4j(topic = "c.AddTask") class AddTask1 extends RecursiveTask<Integer> { int n; public AddTask1(int n) { this.n = n; } @Override public String toString() { return "{" + n + '}'; } @Override protected Integer compute() { if (n == 1) { log.debug("join() {}", n); return n; } AddTask1 t1 = new AddTask1(n - 1); t1.fork(); log.debug("fork() {} + {}", n, t1); int result = n + t1.join(); log.debug("join() {} + {} = {}", n, t1, result); return result; } } @Slf4j(topic = "c.AddTask") class AddTask2 extends RecursiveTask<Integer> { int begin; int end; public AddTask2(int begin, int end) { this.begin = begin; this.end = end; } @Override public String toString() { return "{" + begin + "," + end + '}'; } @Override protected Integer compute() { if (begin == end) { log.debug("join() {}", begin); return begin; } if (end - begin == 1) { log.debug("join() {} + {} = {}", begin, end, end + begin); return end + begin; } int mid = (end + begin) / 2; AddTask2 t1 = new AddTask2(begin, mid - 1); t1.fork(); AddTask2 t2 = new AddTask2(mid + 1, end); t2.fork(); log.debug("fork() {} + {} + {} = ?", mid, t1, t2); int result = mid + t1.join() + t2.join(); log.debug("join() {} + {} + {} = {}", mid, t1, t2, result); return result; } } @Slf4j(topic = "c.AddTask") class AddTask3 extends RecursiveTask<Integer> { int begin; int end; public AddTask3(int begin, int end) { this.begin = begin; this.end = end; } @Override public String toString() { return "{" + begin + "," + end + '}'; } @Override protected Integer compute() { if (begin == end) { log.debug("join() {}", begin); return begin; } if (end - begin == 1) { log.debug("join() {} + {} = {}", begin, end, end + begin); return end + begin; } int mid = (end + begin) / 2; AddTask3 t1 = new AddTask3(begin, mid); t1.fork(); AddTask3 t2 = new AddTask3(mid + 1, end); t2.fork(); log.debug("fork() {} + {} = ?", t1, t2); int result = t1.join() + t2.join(); log.debug("join() {} + {} = {}", t1, t2, result); return result; } }
10:10:14.568 c.AddTask [ForkJoinPool-1-worker-1] - fork() {1,3} + {4,5} = ? 10:10:14.568 c.AddTask [ForkJoinPool-1-worker-0] - join() 1 + 2 = 3 10:10:14.568 c.AddTask [ForkJoinPool-1-worker-3] - join() 4 + 5 = 9 10:10:14.568 c.AddTask [ForkJoinPool-1-worker-2] - fork() {1,2} + {3,3} = ? 10:10:14.573 c.AddTask [ForkJoinPool-1-worker-1] - join() 3 10:10:14.573 c.AddTask [ForkJoinPool-1-worker-2] - join() {1,2} + {3,3} = 6 10:10:14.573 c.AddTask [ForkJoinPool-1-worker-1] - join() {1,3} + {4,5} = 15 15
流程图

核心数据结构
与ThreadPoolExector不同的是,除一个全局的任务队列之外,每个线程还有一个自己的局部队列。
public class ForkJoinPool extends AbstractExecutorService { // 状态变量,类似于ThreadPoolExecutor中的ctl变量。 volatile long ctl; // 下一个worker的下标 int indexSeed; // 工作线程队列 WorkQueue[] workQueues; // 工作线程工厂 final ForkJoinWorkerThreadFactory factory; static final class WorkQueue { volatile int source; // source queue id, or sentinel int id; // 在ForkJoinPool的workQueues数组中的下标 int base; // 队列尾部指针 int top; // 队列头指针 volatile int phase; // versioned, negative: queued, 1: locked int stackPred; // pool stack (ctl) predecessor link int nsteals; // number of steals ForkJoinTask<?>[] array; // 工作线程的局部队列 final ForkJoinPool pool; // the containing pool (may be null) final ForkJoinWorkerThread owner; // 该工作队列的所有者线程,null表示共享的 } public class ForkJoinWorkerThread extends Thread { // 当前工作线程所在的线程池,反向引用 final ForkJoinPool pool; // 工作队列 final ForkJoinPool.WorkQueue workQueue; } }
工作窃取队列
关于上面的全局队列,有一个关键点需要说明:它并非使用BlockingQueue,而是基于一个普通的数组得以实现。
这个队列又名工作窃取队列,为 ForkJoinPool 的工作窃取算法提供服务。在 ForkJoinPool开篇的注释中,Doug Lea 特别提到了工作窃取队列的实现,其陈述来自如下两篇论文:"Dynamic Circular Work-Stealing Deque" by Chase and Lev,SPAA 2005与"Idempotent work stealing" by Michael,Saraswat,and Vechev,PPoPP 2009。读者可以在网上查阅相应论文。
所谓工作窃取算法,是指一个Worker线程在执行完毕自己队列中的任务之后,可以窃取其他线程队列中的任务来执行,从而实现负载均衡,以防有的线程很空闲,有的线程很忙。这个过程要用到工作窃取队列。


这个队列只有如下几个操作:
- Worker线程自己,在队列头部,通过对top指针执行加、减操作,实现入队或出队,这是单线程的。
- 其他Worker线程,在队列尾部,通过对base进行累加,实现出队操作,也就是窃取,这是多线程的,需要通过CAS操作。
这个队列,在Dynamic Circular Work-Stealing Deque这篇论文中被称为dynamic-cyclic-array。之所以这样命名,是因为有两个关键点:
- 整个队列是环形的,也就是一个数组实现的RingBuffer。并且base会一直累加,不会减小;top会累加、减小。最后,base、top的值都会大于整个数组的长度,只是计算数组下标的时候,会取top&(queue.length-1),base&(queue.length-1)。因为queue.length是2的整数次方,这里也就是对queue.length进行取模操作。当top-base=queue.length-1 的时候,队列为满,此时需要扩容;当top=base的时候,队列为空,Worker线程即将进入阻塞状态。
- 当队列满了之后会扩容,所以被称为是动态的。
但这就涉及一个棘手的问题:多个线程同时在读写这个队列,如何实现在不加锁的情况下一边读写、一边扩容呢?
通过分析工作窃取队列的特性,我们会发现:在 base 一端,是多线程访问的,但它们只会使base变大,也就是使队列中的元素变少。所以队列为满,一定发生在top一端,对top进行累加的时候,这一端却是单线程的!队列的扩容恰好利用了这个单线程的特性!即在扩容过程中,不可能有其他线程对top
进行修改,只有线程对base进行修改!
下图为工作窃取队列扩容示意图。扩容之后,数组长度变成之前的二倍,但top、base的值是不变的!通过top、base对新的数组长度取模,仍然可以定位到元素在新数组中的位置。


下面结合WorkQueue扩容的代码进一步分析。




final void growArray(boolean locked) { ForkJoinTask<?>[] newA = null; try { ForkJoinTask<?>[] oldA; int oldSize, newSize; // 当旧的array不是null,旧的array包含元素 // 并且新的数组长度小于队列最大长度,并且新的长度大于0 if ((oldA = array) != null && (oldSize = oldA.length) > 0 && (newSize = oldSize << 1) <= MAXIMUM_QUEUE_CAPACITY && newSize > 0) { try { // 创建新数组 newA = new ForkJoinTask<?>[newSize]; } catch (OutOfMemoryError ex) { } if (newA != null) { // poll from old array, push to new int oldMask = oldSize - 1, newMask = newSize - 1; for (int s = top - 1, k = oldMask; k >= 0; --k) { // 逐个复制 ForkJoinTask<?> x = (ForkJoinTask<?>) // 获取旧的值,将原来的设置为null QA.getAndSet(oldA, s & oldMask, null); if (x != null) newA[s-- & newMask] = x; else break; } array = newA; VarHandle.releaseFence(); } } } finally { if (locked) phase = 0; } if (newA == null) throw new RejectedExecutionException("Queue capacity exceeded"); }
ForkJoinPool状态控制
状态变量ctl解析
类似于ThreadPoolExecutor,在ForkJoinPool中也有一个ctl变量负责表达ForkJoinPool的整个生命周期和相关的各种状态。不过ctl变量更加复杂,是一个long型变量,代码如下所示。
public class ForkJoinPool extends AbstractExecutorService { // ... // 线程池状态变量 volatile long ctl; private static final long SP_MASK = 0xffffffffL; private static final long UC_MASK = ~SP_MASK; private static final int RC_SHIFT = 48; private static final long RC_UNIT = 0x0001L << RC_SHIFT; private static final long RC_MASK = 0xffffL << RC_SHIFT; private static final int TC_SHIFT = 32; private static final long TC_UNIT = 0x0001L << TC_SHIFT; private static final long TC_MASK = 0xffffL << TC_SHIFT; private static final long ADD_WORKER = 0x0001L << (TC_SHIFT + 15); // sign // ... }


ctl变量的64个比特位被分成五部分:
- AC:最高的16个比特位,表示Active线程数-parallelism,parallelism是上面的构造方法传进 去的参数;
- TC:次高的16个比特位,表示Total线程数-parallelism;
- ST:1个比特位,如果是1,表示整个ForkJoinPool正在关闭;
- EC:15个比特位,表示阻塞栈的栈顶线程的wait count(关于什么是wait count,接下来解 释);
- ID:16个比特位,表示阻塞栈的栈顶线程对应的id。


阻塞栈Treiber Stack
什么叫阻塞栈呢?
要实现多个线程的阻塞、唤醒,除了park/unpark这一对操作原语,还需要一个无锁链表实现的阻塞队列,把所有阻塞的线程串在一起。
在ForkJoinPool中,没有使用阻塞队列,而是使用了阻塞栈。把所有空闲的Worker线程放在一个栈里面,这个栈同样通过链表来实现,名为Treiber Stack。
下图为所有阻塞的Worker线程组成的Treiber Stack。


首先,WorkQueue有一个id变量,记录了自己在WorkQueue[]数组中的下标位置,id变量就相当于每个WorkQueue或ForkJoinWorkerThread对象的地址;


其次,ForkJoinWorkerThread还有一个stackPred变量,记录了前一个阻塞线程的id,这个stackPred变量就相当于链表的next指针,把所有的阻塞线程串联在一起,组成一个Treiber Stack。
最后,ctl变量的最低16位,记录了栈的栈顶线程的id;中间的15位,记录了栈顶线程被阻塞的次数,也称为wait count。
ctl变量的初始值
构造方法中,有如下的代码:


因为在初始的时候,ForkJoinPool 中的线程个数为 0,所以 AC=0-parallelism,TC=0-parallelism。这意味着只有高32位的AC、TC 两个部分填充了值,低32位都是0填充。