

insert … select 语句
表t和t2的表结构、初始化数据语句如下,今天的例子我们还是针对这两个表展开。
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t
现在,我们一起来看看为什么在可重复读隔离级别下,
binlog_format=statement时执行:insert into t2(c,d) select c,d from t;
这个语句时,需要对表t的所有行和间隙加锁呢?
其实,这个问题我们需要考虑的还是日志和数据的一致性。我们看下这个执行序列:


实际的执行效果是,如果session B先执行,由于这个语句对表t主键索引加了(-∞,1]这个next-key lock,会在语句执行完成后,才允许session A的insert语句执行。
但如果没有锁的话,就可能出现session B的insert语句先执行,但是后写入binlog的情况。于是,在
binlog_format=statement的情况下,binlog里面就记录了这样的语句序列:insert into t values(-1,-1,-1); insert into t2(c,d) select c,d from t;
这个语句到了备库执行,就会把
id=-1这一行也写到表t2中,出现主备不一致。insert 循环写入
当然了,执行
insert … select 的时候,对目标表也不是锁全表,而是只锁住需要访问的资源。如果现在有这么一个需求:要往表t2中插入一行数据,这一行的c值是表t中c值的最大值加1。
此时,我们可以这么写这条SQL语句 :
insert into t2(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
这个语句的加锁范围,就是表t索引c上的(3,4]和(4,supremum]这两个next-key lock,以及主键索引上id=4这一行。
它的执行流程也比较简单,从表t中按照索引c倒序,扫描第一行,拿到结果写入到表t2中。
因此整条语句的扫描行数是1。
这个语句执行的慢查询日志(slow log),如下图所示:


慢查询日志--将数据插入表t2
通过这个慢查询日志,我们看到
Rows_examined=1,正好验证了执行这条语句的扫描行数为1。那么,如果我们是要把这样的一行数据插入到表t中的话:
insert into t(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
语句的执行流程是怎样的?扫描行数又是多少呢?
这时候,我们再看慢查询日志就会发现不对了。


可以看到,这时候的
Rows_examined的值是5。我在前面的文章中提到过,希望你都能够学会用explain的结果来“脑补”整条语句的执行过程。今天,我们就来一起试试。
如下图所示就是这条语句的explain结果。


从Extra字段可以看到“
Using temporary”字样,表示这个语句用到了临时表。也就是说,执行过程中,需要把表t的内容读出来,写入临时表。图中rows显示的是1,我们不妨先对这个语句的执行流程做一个猜测:如果说是把子查询的结果读出来(扫描1行),写入临时表,然后再从临时表读出来(扫描1行),写回表t中。那么,这个语句的扫描行数就应该是2,而不是5。
所以,这个猜测不对。实际上,Explain结果里的rows=1是因为受到了limit 1 的影响。
从另一个角度考虑的话,我们可以看看InnoDB扫描了多少行。如下图所示,是在执行这个语句前后查看
Innodb_rows_read的结果。
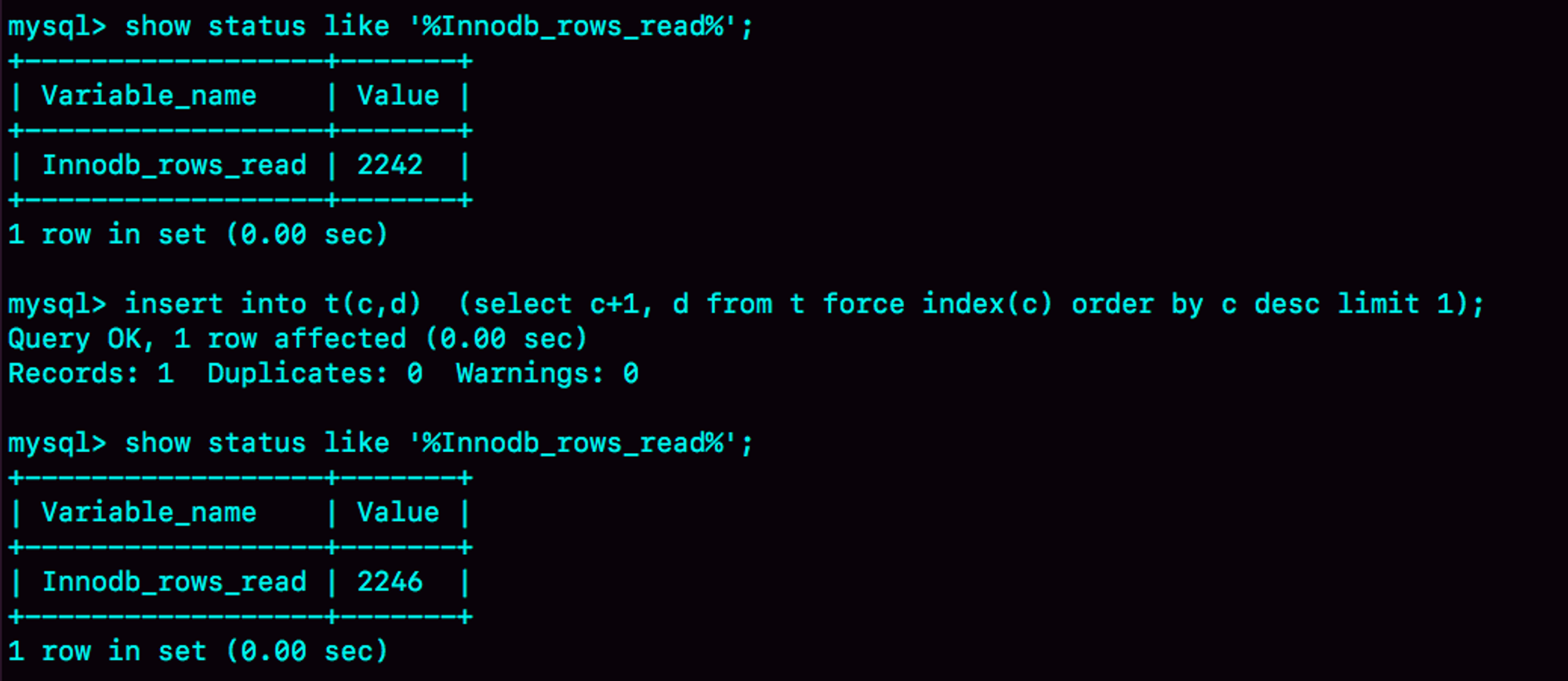
Innodb_rows_read变化可以看到,这个语句执行前后,
Innodb_rows_read的值增加了4。因为默认临时表是使用Memory引擎的,所以这4行查的都是表t,也就是说对表t做了全表扫描。这样,我们就把整个执行过程理清楚了:
- 创建临时表,表里有两个字段c和d。
- 按照索引c扫描表t,依次取c=4、3、2、1,然后回表,读到c和d的值写入临时表。这时,Rows_examined=4。
- 由于语义里面有limit 1,所以只取了临时表的第一行,再插入到表t中。这时,
Rows_examined的值加1,变成了5。
也就是说,这个语句会导致在表t上做全表扫描,并且会给索引c上的所有间隙都加上共享的next-key lock。所以,这个语句执行期间,其他事务不能在这个表上插入数据。
至于这个语句的执行为什么需要临时表,原因是这类一边遍历数据,一边更新数据的情况,如果读出来的数据直接写回原表,就可能在遍历过程中,读到刚刚插入的记录,新插入的记录如果参与计算逻辑,就跟语义不符。
由于实现上这个语句没有在子查询中就直接使用limit 1,从而导致了这个语句的执行需要遍历整个表t。它的优化方法也比较简单,就是用前面介绍的方法,先insert into到临时表temp_t,这样就只需要扫描一行;然后再从表temp_t里面取出这行数据插入表t1。
当然,由于这个语句涉及的数据量很小,你可以考虑使用内存临时表来做这个优化。使用内存临时表优化时,语句序列的写法如下:
create temporary table temp_t(c int,d int) engine=memory; insert into temp_t (select c+1, d from t force index(c) order by c desc limit 1); insert into t select * from temp_t; drop table temp_t;
insert 唯一键冲突
前面的两个例子是使用
insert … select的情况,接下来我要介绍的这个例子就是最常见的insert语句出现唯一键冲突的情况。对于有唯一键的表,插入数据时出现唯一键冲突也是常见的情况了。我先给你举一个简单的唯一键冲突的例子。


这个例子也是在可重复读(
repeatable read)隔离级别下执行的。可以看到,session B要执行的insert语句进入了锁等待状态。也就是说,session A执行的insert语句,发生唯一键冲突的时候,并不只是简单地报错返回,还在冲突的索引上加了锁。我们前面说过,一个next-key lock就是由它右边界的值定义的。这时候,session A持有索引c上的(5,10]共享next-key lock(读锁)。
至于为什么要加这个读锁,其实我也没有找到合理的解释。从作用上来看,这样做可以避免这一行被别的事务删掉。
这里官方文档有一个描述错误,认为如果冲突的是主键索引,就加记录锁,唯一索引才加next-key lock。但实际上,这两类索引冲突加的都是next-key lock。
备注:这个bug,是我在写这篇文章查阅文档时发现的,已经发给官方并被verified了。
有同学在前面文章的评论区问到,在有多个唯一索引的表中并发插入数据时,会出现死锁。但是,由于他没有提供复现方法或者现场,我也无法做分析。所以,我建议你在评论区发问题的时候,尽量同时附上复现方法,或者现场信息,这样我才好和你一起分析问题。
这里,我就先和你分享一个经典的死锁场景,如果你还遇到过其他唯一键冲突导致的死锁场景,也欢迎给我留言。


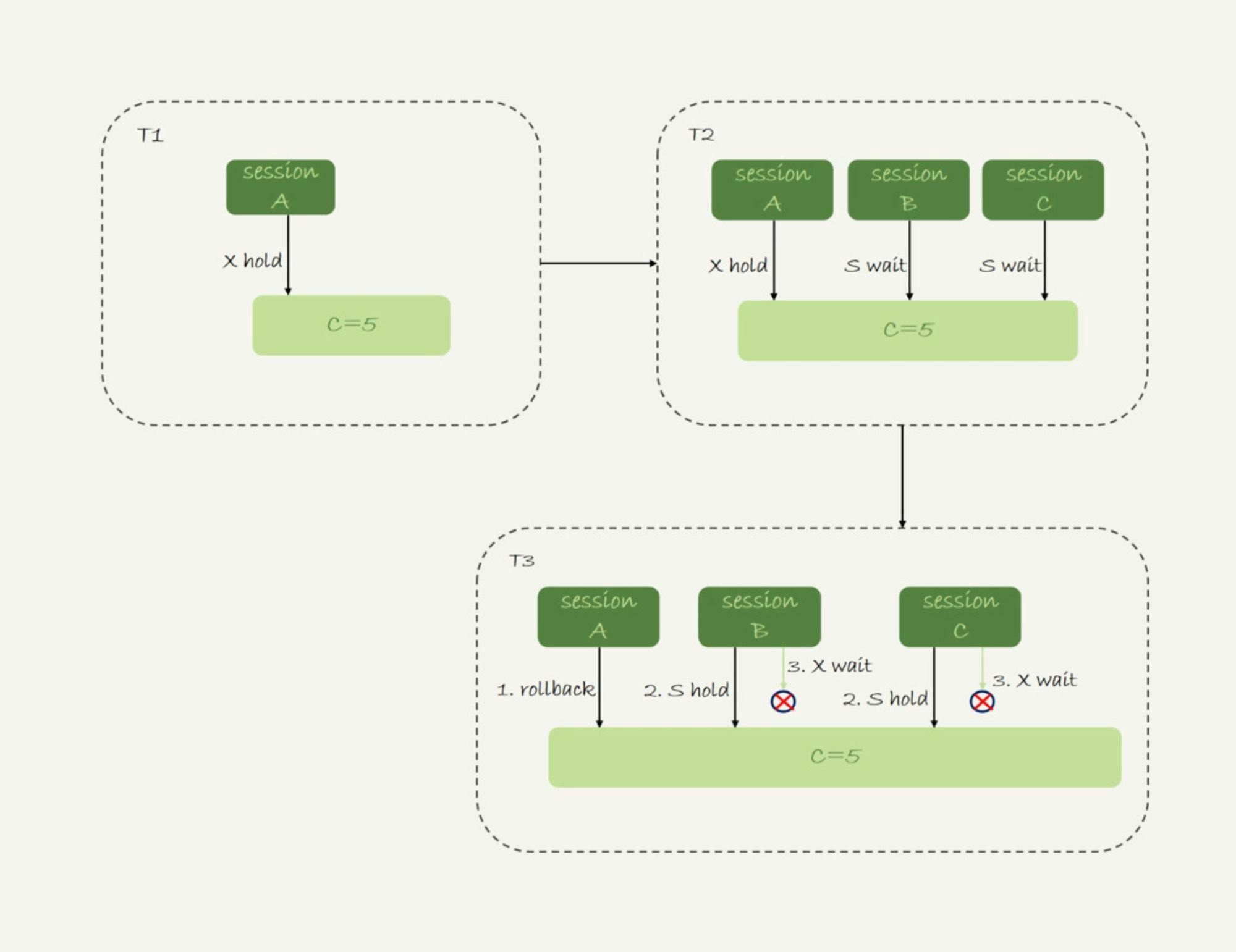
在session A执行rollback语句回滚的时候,session C几乎同时发现死锁并返回。
这个死锁产生的逻辑是这样的:
- 在T1时刻,启动session A,并执行insert语句,此时在索引c的c=5上加了记录锁。注意,这个索引是唯一索引,因此退化为记录锁(加锁规则)。
- 在T2时刻,session B要执行相同的insert语句,发现了唯一键冲突,加上读锁;同样地,session C也在索引c上,c=5这一个记录上,加了读锁。
- T3时刻,session A回滚。这时候,session B和session C都试图继续执行插入操作,都要加上写锁。两个session都要等待对方的行锁,所以就出现了死锁。
这个流程的状态变化图如下所示。

insert into … on duplicate key update
上面这个例子是主键冲突后直接报错,如果是改写成
insert into t values(11,10,10) on duplicate key update d=100;
的话,就会给索引c上(5,10] 加一个排他的next-key lock(写锁)。
insert into … on duplicate key update 这个语义的逻辑是,插入一行数据,如果碰到唯一键约束,就执行后面的更新语句。注意,如果有多个列违反了唯一性约束,就会按照索引的顺序,修改跟第一个索引冲突的行。
现在表t里面已经有了(1,1,1)和(2,2,2)这两行,我们再来看看下面这个语句执行的效果:

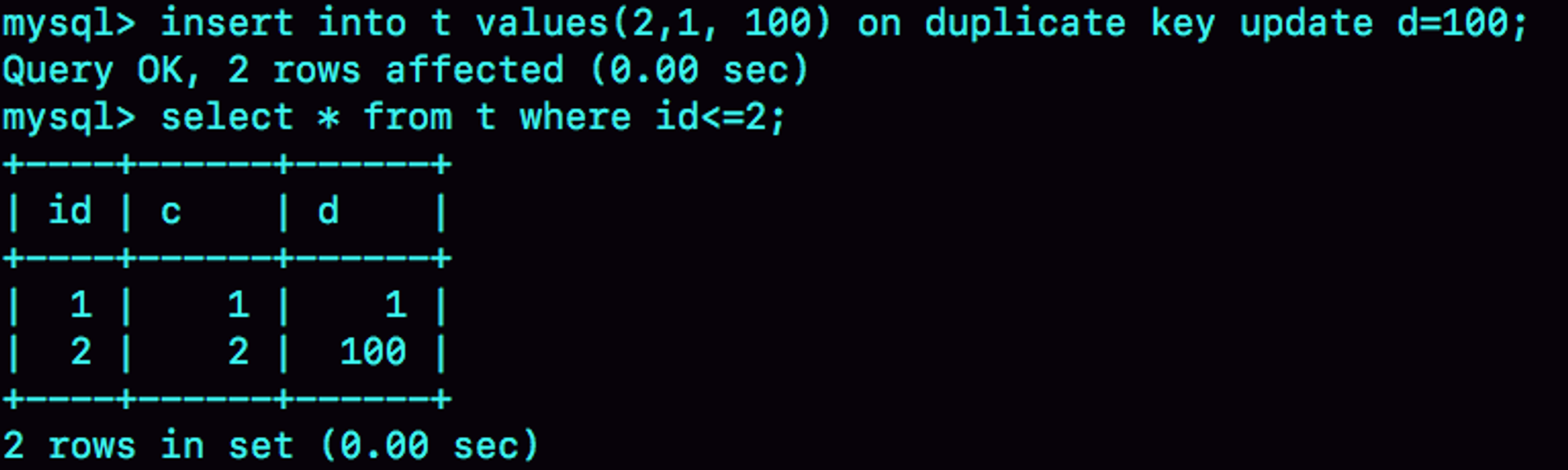
可以看到,主键id是先判断的,MySQL认为这个语句跟id=2这一行冲突,所以修改的是id=2的行。
需要注意的是,执行这条语句的
affected rows返回的是2,很容易造成误解。实际上,真正更新的只有一行,只是在代码实现上,insert和update都认为自己成功了,update计数加了1, insert计数也加了1。你平时在两个表之间拷贝数据用的是什么方法,有什么注意事项吗?在你的应用场景里,这个方法,相较于其他方法的优势是什么呢?
A1
我用的最多还是insert into select 。如果数量比较大,会加上limit 100,000这种。并且看看后面的select条件是否走索引。缺点是会锁select的表。方法二:导出成excel,然后拼sql 成 insert into values(),(),()的形式。方法3,写类似淘宝调动的定时任务,任务的逻辑是查询100条记录,然后多个线程分到几个任务执行,比如是个线程,每个线程10条记录,插入后,在查询新的100条记录处理。
A2
1 关于insert造成死锁的情况,我之前做过测试,事务1并非只有insert,delete和update都可能造成死锁问题,核心还是插入唯一值冲突导致的.我们线上的处理办法是 1 去掉唯一值检测 2减少重复值的插入 3降低并发线程数量
2 关于数据拷贝大表我建议采用pt-archiver,这个工具能自动控制频率和速度,效果很不错,提议在低峰期进行数据操作
如果可以控制对源表的扫描行数和加锁范围很小的话,我们简单地使用insert … select 语句即可实现。
当然,为了避免对源表加读锁,更稳妥的方案是先将数据写到外部文本文件,然后再写回目标表。这时,有两种常用的方法。接下来的内容,我会和你详细展开一下这两种方法。
为了便于说明,我还是先创建一个表db1.t,并插入1000行数据,同时创建一个相同结构的表db2.t。
create database db1; use db1; create table t(id int primary key, a int, b int, index(a))engine=innodb; delimiter ;; create procedure idata() begin declare i int; set i=1; while(i<=1000)do insert into t values(i,i,i); set i=i+1; end while; end;; delimiter ; call idata(); create database db2; create table db2.t like db1.t
假设,我们要把db1.t里面a>900的数据行导出来,插入到db2.t中。
mysqldump方法
一种方法是,使用mysqldump命令将数据导出成一组INSERT语句。你可以使用下面的命令:
mysqldump -h$host -P$port -u$user --add-locks=0 --no-create-info --single-transaction --set-gtid-purged=OFF db1 t --where="a>900" --result-file=/client_tmp/t.sql
把结果输出到临时文件。
这条命令中,主要参数含义如下:
–single-transaction的作用是,在导出数据的时候不需要对表db1.t加表锁,而是使用START TRANSACTION WITH CONSISTENT SNAPSHOT的方法;
–add-locks设置为0,表示在输出的文件结果里,不增加" LOCK TABLEStWRITE;" ;
–no-create-info的意思是,不需要导出表结构;
–set-gtid-purged=off表示的是,不输出跟GTID相关的信息;
–result-file指定了输出文件的路径,其中client表示生成的文件是在客户端机器上的。
通过这条
mysqldump命令生成的t.sql文件中就包含了如下图所示的INSERT语句。

mysqldump输出文件的部分结果可以看到,一条INSERT语句里面会包含多个value对,这是为了后续用这个文件来写入数据的时候,执行速度可以更快。
如果你希望生成的文件中一条INSERT语句只插入一行数据的话,可以在执行
mysqldump命令时,加上参数–skip-extended-insert。然后,你可以通过下面这条命令,将这些INSERT语句放到db2库里去执行。
mysql -h127.0.0.1 -P13000 -uroot db2 -e "source /client_tmp/t.sql"
需要说明的是,source并不是一条SQL语句,而是一个客户端命令。mysql客户端执行这个命令的流程是这样的:
- 打开文件,默认以分号为结尾读取一条条的SQL语句;
- 将SQL语句发送到服务端执行。
也就是说,服务端执行的并不是这个“source t.sql"语句,而是INSERT语句。所以,不论是在慢查询日志(slow log),还是在binlog,记录的都是这些要被真正执行的INSERT语句。
导出CSV文件
另一种方法是直接将结果导出成.csv文件。MySQL提供了下面的语法,用来将查询结果导出到服务端本地目录:
select * from db1.t where a>900 into outfile '/server_tmp/t.csv';
我们在使用这条语句时,需要注意如下几点。
- 这条语句会将结果保存在服务端。如果你执行命令的客户端和MySQL服务端不在同一个机器上,客户端机器的临时目录下是不会生成t.csv文件的。
into outfile指定了文件的生成位置(/server_tmp/),这个位置必须受参数secure_file_priv的限制。参数secure_file_priv的可选值和作用分别是:- 如果设置为empty,表示不限制文件生成的位置,这是不安全的设置;
- 如果设置为一个表示路径的字符串,就要求生成的文件只能放在这个指定的目录,或者它的子目录;
- 如果设置为NULL,就表示禁止在这个MySQL实例上执行
select … into outfile操作。
- 这条命令不会帮你覆盖文件,因此你需要确保
/server_tmp/t.csv这个文件不存在,否则执行语句时就会因为有同名文件的存在而报错。
- 这条命令生成的文本文件中,原则上一个数据行对应文本文件的一行。但是,如果字段中包含换行符,在生成的文本中也会有换行符。不过类似换行符、制表符这类符号,前面都会跟上“\”这个转义符,这样就可以跟字段之间、数据行之间的分隔符区分开。
得到.csv导出文件后,你就可以用下面的
load data命令将数据导入到目标表db2.t中。load data infile '/server_tmp/t.csv' into table db2.t;
这条语句的执行流程如下所示。
- 打开文件
/server_tmp/t.csv,以制表符(\t)作为字段间的分隔符,以换行符(\n)作为记录之间的分隔符,进行数据读取;
- 启动事务。
- 判断每一行的字段数与表db2.t是否相同:
- 若不相同,则直接报错,事务回滚;
- 若相同,则构造成一行,调用InnoDB引擎接口,写入到表中。
- 重复步骤3,直到
/server_tmp/t.csv整个文件读入完成,提交事务。
你可能有一个疑问,如果
binlog_format=statement,这个load语句记录到binlog里以后,怎么在备库重放呢?由于
/server_tmp/t.csv文件只保存在主库所在的主机上,如果只是把这条语句原文写到binlog中,在备库执行的时候,备库的本地机器上没有这个文件,就会导致主备同步停止。所以,这条语句执行的完整流程,其实是下面这样的。
- 主库执行完成后,将
/server_tmp/t.csv文件的内容直接写到binlog文件中。
- 往binlog文件中写入语句
load data local infile ‘/tmp/SQL_LOAD_MB-1-0’ INTO TABLE `db2`.`t`。
- 把这个binlog日志传到备库。
- 备库的apply线程在执行这个事务日志时:
- 先将binlog中t.csv文件的内容读出来,写入到本地临时目录
/tmp/SQL_LOAD_MB-1-0中; - 再执行load data语句,往备库的db2.t表中插入跟主库相同的数据。
执行流程如下图所示:
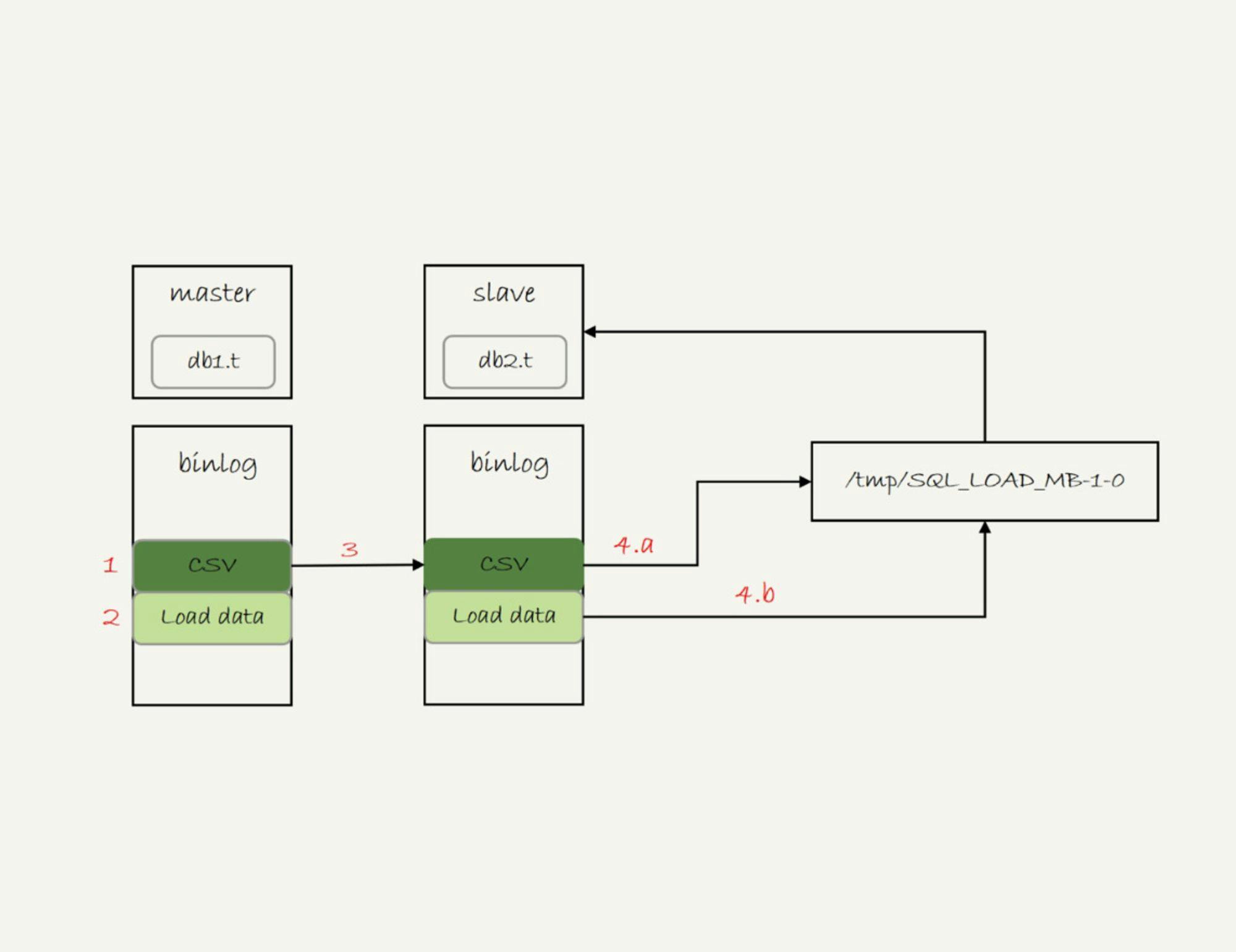
load data的同步流程注意,这里备库执行的
load data语句里面,多了一个“local”。它的意思是“将执行这条命令的客户端所在机器的本地文件/tmp/SQL_LOAD_MB-1-0的内容,加载到目标表db2.t中”。也就是说,
load data命令有两种用法:- 不加“local”,是读取服务端的文件,这个文件必须在
secure_file_priv指定的目录或子目录下;
- 加上“local”,读取的是客户端的文件,只要mysql客户端有访问这个文件的权限即可。这时候,MySQL客户端会先把本地文件传给服务端,然后执行上述的
load data流程。
另外需要注意的是,
select …into outfile方法不会生成表结构文件, 所以我们导数据时还需要单独的命令得到表结构定义。mysqldump提供了一个–tab参数,可以同时导出表结构定义文件和csv数据文件。这条命令的使用方法如下:mysqldump -h$host -P$port -u$user ---single-transaction --set-gtid-purged=OFF db1 t --where="a>900" --tab=$secure_file_priv
这条命令会在
$secure_file_priv定义的目录下,创建一个t.sql文件保存建表语句,同时创建一个t.txt文件保存CSV数据。物理拷贝方法
前面我们提到的
mysqldump方法和导出CSV文件的方法,都是逻辑导数据的方法,也就是将数据从表db1.t中读出来,生成文本,然后再写入目标表db2.t中。你可能会问,有物理导数据的方法吗?比如,直接把db1.t表的.frm文件和.ibd文件拷贝到db2目录下,是否可行呢?
答案是不行的。
因为,一个InnoDB表,除了包含这两个物理文件外,还需要在数据字典中注册。直接拷贝这两个文件的话,因为数据字典中没有db2.t这个表,系统是不会识别和接受它们的。
不过,在MySQL 5.6版本引入了可传输表空间(
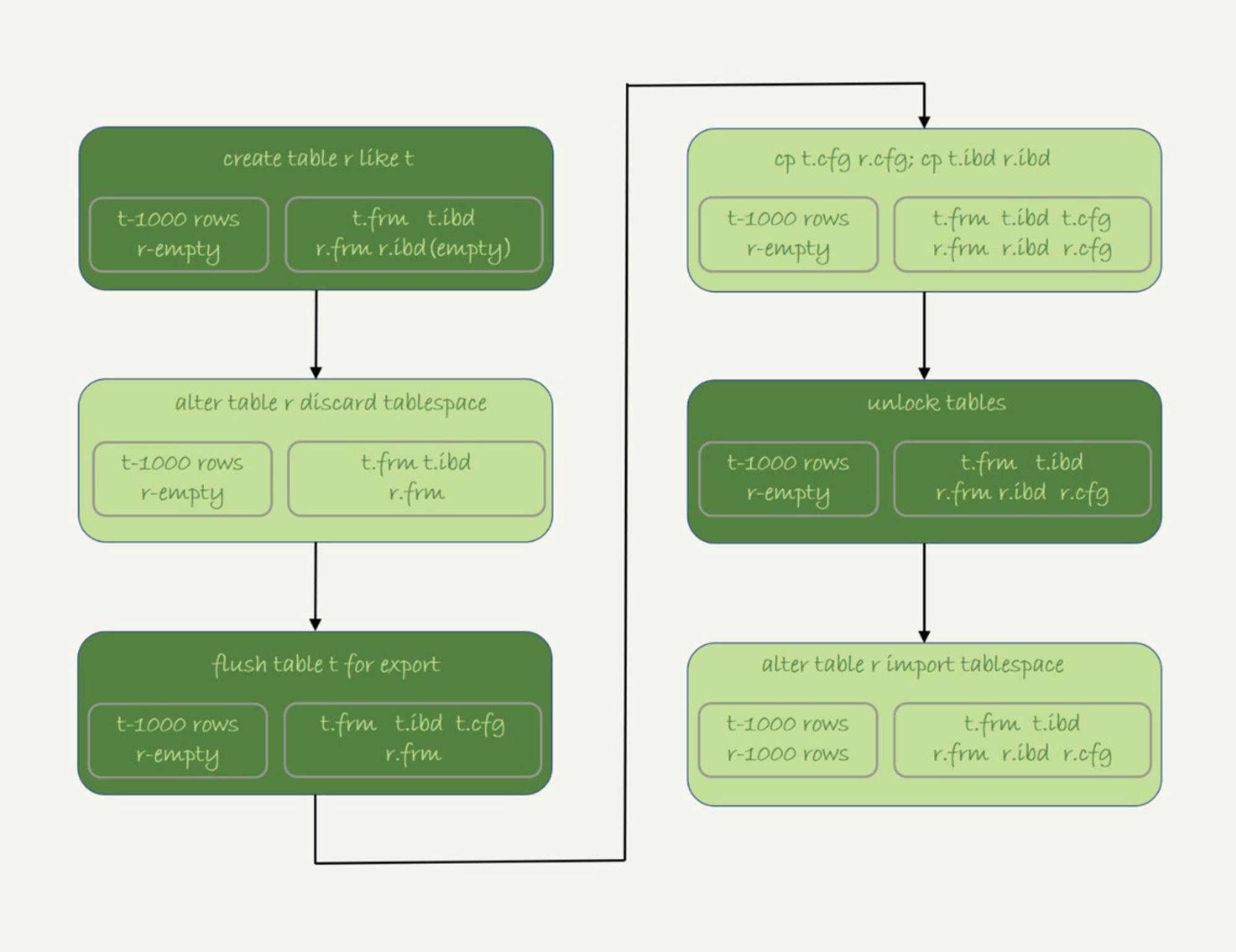
transportable tablespace)的方法,可以通过导出+导入表空间的方式,实现物理拷贝表的功能。假设我们现在的目标是在db1库下,复制一个跟表t相同的表r,具体的执行步骤如下:
- 执行
create table r like t,创建一个相同表结构的空表;
- 执行
alter table r discard tablespace,这时候r.ibd文件会被删除;
- 执行
flush table t for export,这时候db1目录下会生成一个t.cfg文件;
- 在db1目录下执行
cp t.cfg r.cfg; cp t.ibd r.ibd;这两个命令(这里需要注意的是,拷贝得到的两个文件,MySQL进程要有读写权限);
- 执行
unlock tables,这时候t.cfg文件会被删除;
- 执行
alter table r import tablespace,将这个r.ibd文件作为表r的新的表空间,由于这个文件的数据内容和t.ibd是相同的,所以表r中就有了和表t相同的数据。
至此,拷贝表数据的操作就完成了。这个流程的执行过程图如下:
关于拷贝表的这个流程,有以下几个注意点:
- 在第3步执行完
flsuh table命令之后,db1.t整个表处于只读状态,直到执行unlock tables命令后才释放读锁;
- 在执行
import tablespace的时候,为了让文件里的表空间id和数据字典中的一致,会修改r.ibd的表空间id。而这个表空间id存在于每一个数据页中。因此,如果是一个很大的文件(比如TB级别),每个数据页都需要修改,所以你会看到这个import语句的执行是需要一些时间的。当然,如果是相比于逻辑导入的方法,import语句的耗时是非常短的。
我们来对比一下这三种方法的优缺点。
- 物理拷贝的方式速度最快,尤其对于大表拷贝来说是最快的方法。如果出现误删表的情况,用备份恢复出误删之前的临时库,然后再把临时库中的表拷贝到生产库上,是恢复数据最快的方法。但是,这种方法的使用也有一定的局限性:
- 必须是全表拷贝,不能只拷贝部分数据;
- 需要到服务器上拷贝数据,在用户无法登录数据库主机的场景下无法使用;
- 由于是通过拷贝物理文件实现的,源表和目标表都是使用InnoDB引擎时才能使用。
- 用mysqldump生成包含INSERT语句文件的方法,可以在where参数增加过滤条件,来实现只导出部分数据。这个方式的不足之一是,不能使用join这种比较复杂的where条件写法。
- 用select … into outfile的方法是最灵活的,支持所有的SQL写法。但,这个方法的缺点之一就是,每次只能导出一张表的数据,而且表结构也需要另外的语句单独备份。
后两种方式都是逻辑备份方式,是可以跨引擎使用的
在
binlog_format=statement时,语句A先获取id=1,然后语句B获取id=2;接着语句B提交,写binlog,然后语句A再写binlog。这时候,如果binlog重放,是不是会发生语句B的id为1,而语句A的id为2的不一致情况呢?首先,这个问题默认了“自增id的生成顺序,和binlog的写入顺序可能是不同的”,这个理解是正确的。
其次,这个问题限定在statement格式下,也是对的。因为row格式的binlog就没有这个问题了,
Write row event里面直接写了每一行的所有字段的值。而至于为什么不会发生不一致的情况,我们来看一下下面的这个例子。
create table t(id int auto_increment primary key); insert into t values(null);


可以看到,在insert语句之前,还有一句
SET INSERT_ID=1。这条命令的意思是,这个线程里下一次需要用到自增值的时候,不论当前表的自增值是多少,固定用1这个值。这个
SET INSERT_ID语句是固定跟在insert语句之前的,主库上语句A的id是1,语句B的id是2,但是写入binlog的顺序先B后A,那么binlog就变成:SET INSERT_ID=2; 语句B; SET INSERT_ID=1; 语句A;
你看,在备库上语句B用到的
INSERT_ID依然是2,跟主库相同。因此,即使两个INSERT语句在主备库的执行顺序不同,自增主键字段的值也不会不一致