

双M的循环复制问题


我们可以认为正常情况下主备的数据是一致的。也就是说,图中A、B两个节点的内容是一致的。其实,上图画的是M-S结构,但实际生产上使用比较多的是双M结构,也就是下图所示的主备切换流程。

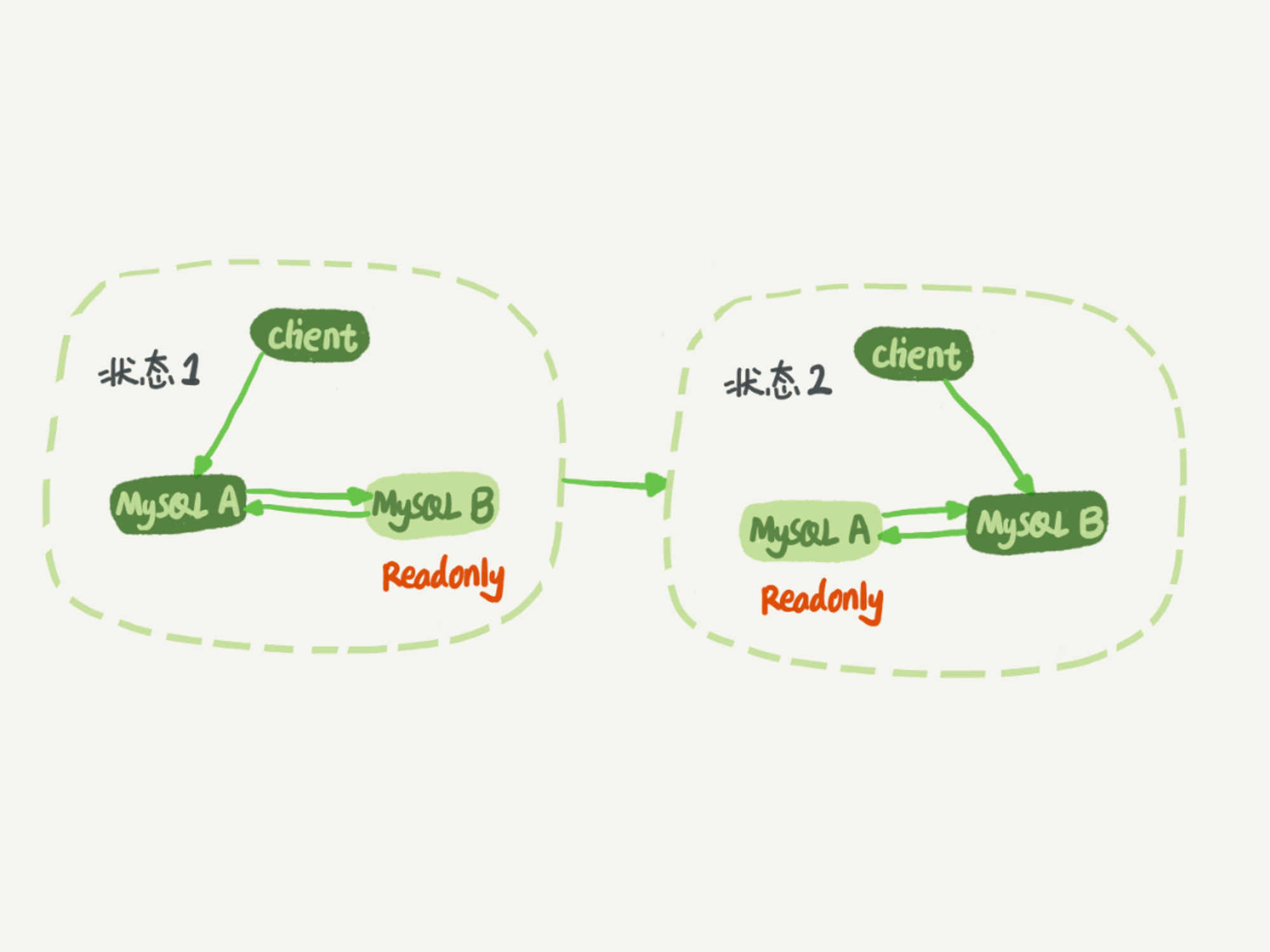
双M结构和M-S结构,其实区别只是多了一条线,即:节点A和B之间总是互为主备关系。这样在切换的时候就不用再修改主备关系。
但是,双M结构还有一个问题需要解决。
业务逻辑在节点A上更新了一条语句,然后再把生成的binlog 发给节点B,节点B执行完这条更新语句后也会生成binlog。(我建议你把参数log_slave_updates设置为on,表示备库执行relay log后生成binlog)。
那么,如果节点A同时是节点B的备库,相当于又把节点B新生成的binlog拿过来执行了一次,然后节点A和B间,会不断地循环执行这个更新语句,也就是循环复制了。这个要怎么解决呢?
server id解决
MySQL在binlog中记录了这个命令第一次执行时所在实例的server id。因此,我们可以用下面的逻辑,来解决两个节点间的循环复制的问题:
- 规定两个库的server id必须不同,如果相同,则它们之间不能设定为主备关系;
- 一个备库接到binlog并在重放的过程中,生成与原binlog的server id相同的新的binlog;
- 每个库在收到从自己的主库发过来的日志后,先判断server id,如果跟自己的相同,表示这个日志是自己生成的,就直接丢弃这个日志。
按照这个逻辑,如果我们设置了双M结构,日志的执行流就会变成这样:
- 从节点A更新的事务,binlog里面记的都是A的server id;
- 传到节点B执行一次以后,节点B生成的binlog 的server id也是A的server id;
- 再传回给节点A,A判断到这个server id与自己的相同,就不会再处理这个日志。所以,死循环在这里就断掉了
说到循环复制问题的时候,我们说MySQL通过判断server id的方式,断掉死循环。但是,这个机制其实并不完备,在某些场景下,还是有可能出现死循环。
- 一种场景是,在一个主库更新事务后,用命令set global server_id=x修改了server_id。等日志再传回来的时候,发现server_id跟自己的server_id不同,就只能执行了。
- 有三个节点的时候,如下图所示,trx1是在节点 B执行的,因此binlog上的server_id就是B,binlog传给节点 A,然后A和A’搭建了双M结构,就会出现循环复制。

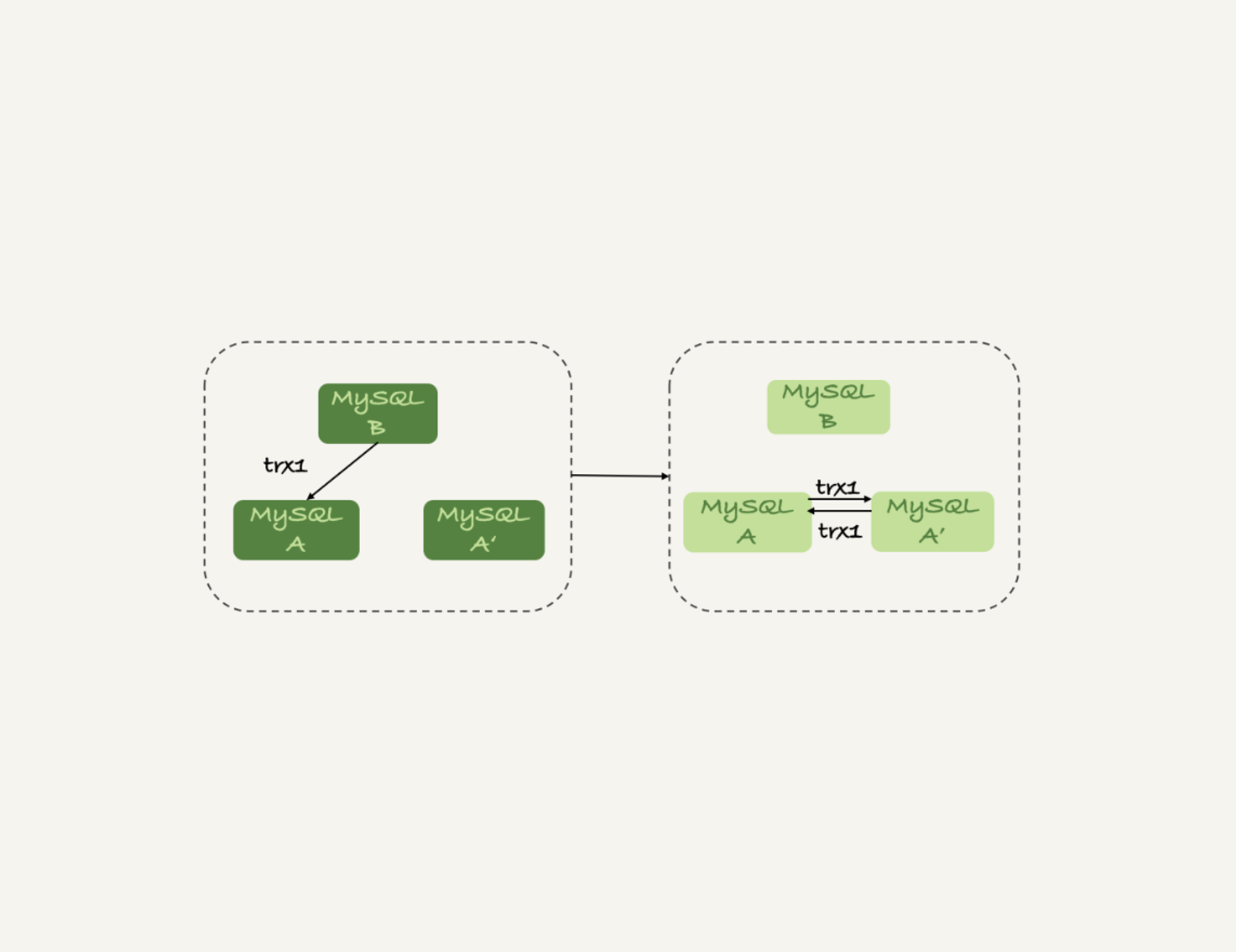
这种三节点复制的场景,做数据库迁移的时候会出现。
如果出现了循环复制,可以在A或者A’上,执行如下命令:
stop slave; CHANGE MASTER TO IGNORE_SERVER_IDS=(server_id_of_B); start slave;
这样这个节点收到日志后就不会再执行。过一段时间后,再执行下面的命令把这个值改回来。
stop slave; CHANGE MASTER TO IGNORE_SERVER_IDS=(); start slave;
使用双主双写还是双主单写?
建议大家使用双主单写,因为双主双写存在以下问题:
- ID冲突
在A主库写入,当A数据未同步到B主库时,对B主库写入,如果采用自动递增容易发生ID主键的冲突。
可以采用MySQL自身的自动增长步长来解决,例如A的主键为1,3,5,7...,B的主键为2,4,6,8... ,但
是对数据库运维、扩展都不友好。
- 更新丢失
同一条记录在两个主库中进行更新,会发生前面覆盖后面的更新丢失
高可用架构如下图所示,其中一个Master提供线上服务,另一个Master作为备胎供高可用切换,Master下游挂载Slave承担读请求。


随着业务发展,架构会从主从模式演变为双主模式,建议用双主单写,再引入高可用组件,例如Keepalived和MMM等工具,实现主库故障自动切换。
MMM架构
MMM(Master-Master Replication Manager for MySQL)是一套用来管理和监控双主复制,支持双主故障切换 的第三方软件。
MMM 使用Perl语言开发,虽然是双主架构,但是业务上同一时间只允许一个节点进行写入操作。下图是基于MMM实现的双主高可用架构。


MMM故障处理机制
MMM 包含writer和reader两类角色,分别对应写节点和读节点。
- 当 writer节点出现故障,程序会自动移除该节点上的VIP
- 写操作切换到 Master2,并将Master2设置为writer
- 将所有Slave节点会指向Master2
除了管理双主节点,MMM 也会管理 Slave 节点,在出现宕机、复制延迟或复制错误,MMM 会移除该节点的 VIP,直到节点恢复正常。
MMM监控机制
MMM 包含monitor和agent两类程序,功能如下:
- monitor:监控集群内数据库的状态,在出现异常时发布切换命令,一般和数据库分开部署。
- agent:运行在每个 MySQL 服务器上的代理进程,monitor 命令的执行者,完成监控的探针工作和具体服务设置,例如设置 VIP(虚拟IP)、指向新同步节点。
MHA架构
MHA(Master High Availability)是一套比较成熟的 MySQL 高可用方案,也是一款优秀的故障切换和主从提升的高可用软件。
在MySQL故障切换过程中,MHA能做到在30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。MHA还支持在线快速将Master切换到其他主机,通常只需0.5-2秒。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器。


组成
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。负责检测master是否宕机、控制故障转移、检查MySQL复制状况等。
MHA Node运行在每台MySQL服务器上,不管是Master角色,还是Slave角色,都称为Node,是被监控管理的对象节点,负责保存和复制master的二进制日志、识别差异的中继日志事件并将其差异的事件应用于其他的slave、清除中继日志。
MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
MHA故障处理机制
- 把宕机master的binlog保存下来
- 根据binlog位置点找到最新的slave
- 用最新slave的relay log修复其它slave
- 将保存下来的binlog在最新的slave上恢复
- 将最新的slave提升为master
- 将其它slave重新指向新提升的master,并开启主从复制
MHA优点
- 自动故障转移快
- 主库崩溃不存在数据一致性问题
- 性能优秀,支持半同步复制和异步复制
- 一个Manager监控节点可以监控多个集群